Tests évolutifs basés sur les données avec ATS fonctionnel
Décomposition fonctionnelle + données découplées = automatisation évolutive
Cette démonstration montre comment Agilitest permet de réaliser data-driven testing véritables data-driven testing combinant :
• Décomposition fonctionnelle (un sous-script réutilisable sous-script remplit le formulaire)
• Séparation complète entre la logique et les données (fichier CSV externe)
• ATS déterministe sans dépendance à l'IA
L'objectif
Au lieu de générer un seul script d'automatisation volumineux, nous concevons :
✅ Un sous-script fonctionnel chargé uniquement de remplir le formulaire
✅ Un script parent qui itère sur un ensemble de données
✅ Un fichier CSV séparé contenant plusieurs profils de test
Cela crée :
• Réutilisabilité
• Évolutivité
• Architecture propre
• Maintenabilité
• Et surtout :l'automatisation finale est purement ATS aucune IA n'est nécessaire pour l'exécuter.
L'IA génère le script et l'arborescence fonctionnelle
L'IA propose un ensemble complet de fichiers de données
ATS son exécution
Cette démonstration montre comment Agilitest permet de réaliser data-driven testing véritables data-driven testing combinant :
• Décomposition fonctionnelle (un sous-script réutilisable sous-script remplit le formulaire)
• Séparation complète entre la logique et les données (fichier CSV externe)
• ATS déterministe sans dépendance à l'IA
L'objectif
Au lieu de générer un seul script d'automatisation volumineux, nous concevons :
✅ Un sous-script fonctionnel chargé uniquement de remplir le formulaire
✅ Un script parent qui itère sur un ensemble de données
✅ Un fichier CSV séparé contenant plusieurs profils de test
Cela crée :
• Réutilisabilité
• Évolutivité
• Architecture propre
• Maintenabilité
• Et surtout :l'automatisation finale est purement ATS aucune IA n'est nécessaire pour l'exécuter.
L'IA génère le script et l'arborescence fonctionnelle
L'IA propose un ensemble complet de fichiers de données
ATS son exécution
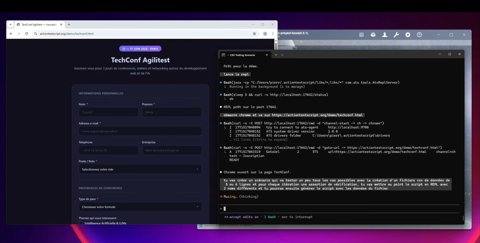
Étape 1 — Définir l'intention basée sur les données
Claude reçoit pour instruction de créer un scénario de test basé sur des données avec plusieurs profils.
L'objectif est de valider plusieurs combinaisons de :
• Rôles
• Types de pass
• Thèmes
• Niveaux d'expérience
• Curseur de budget
• Champs facultatifs
Au lieu de dupliquer la logique, nous allons factoriser le comportement.
L'objectif est de valider plusieurs combinaisons de :
• Rôles
• Types de pass
• Thèmes
• Niveaux d'expérience
• Curseur de budget
• Champs facultatifs
Au lieu de dupliquer la logique, nous allons factoriser le comportement.
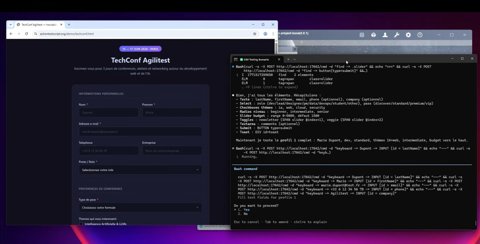
Étape 2 — Identification des éléments du formulaire
À l'aide du REPL, Claude identifie tous les composants interactifs :
• Entrées de texte
• Champs de sélection
• Cases à cocher
• Boutons radio
• Curseur
• Boutons bascules
• Bouton Soumettre
Cela nous permet de créer un sous-script fonctionnel fiable.
• Entrées de texte
• Champs de sélection
• Cases à cocher
• Boutons radio
• Curseur
• Boutons bascules
• Bouton Soumettre
Cela nous permet de créer un sous-script fonctionnel fiable.

Étape 3 — Première entrée fonctionnelle
Un premier profil est saisi de manière interactive pour validation :
• Sélecteurs corrects
• Comportement attendu
• Contrôle de la valeur du curseur budgétaire
Cela permet de valider le flux fonctionnel avant de le généraliser.
• Sélecteurs corrects
• Comportement attendu
• Contrôle de la valeur du curseur budgétaire
Cela permet de valider le flux fonctionnel avant de le généraliser.
Étape 4 — Curseur graphique vs valeur réelle
Bien que le curseur soit graphique, ATS la valeur numérique réelle pour l'assertion.
Cela garantit :
• Interaction visuelle
• Vérification fonctionnelle
• Validation déterministe
Nous validons Métier réelles, et non les pixels.
Cela garantit :
• Interaction visuelle
• Vérification fonctionnelle
• Validation déterministe
Nous validons Métier réelles, et non les pixels.
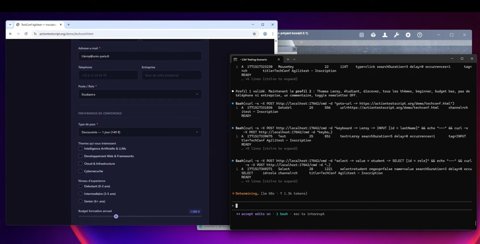
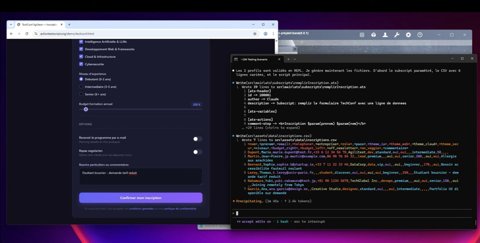
Étape 5 — Deuxième validation du profil
Un deuxième profil est testé pour confirmer :
• Différent rôle
• Différente passe
• Différent budget
• Champs facultatifs laissés vides
Cela garantit que le flux prend en charge des données variables.
• Différent rôle
• Différente passe
• Différent budget
• Champs facultatifs laissés vides
Cela garantit que le flux prend en charge des données variables.
Étape 6 — Création du sous-script fonctionnel sous-script du fichier de données
Claude génère :
Un sous-script réutilisable :
Le fichier CSV ne contient que des données.
Voici le principe fondamental : Logique ≠ Données
Un sous-script réutilisable :
remplirInscription.ats
Un fichier CSV : inscriptions.csv
Le sous-script uniquement la logique fonctionnelle permettant de remplir le formulaire.Le fichier CSV ne contient que des données.
Voici le principe fondamental : Logique ≠ Données
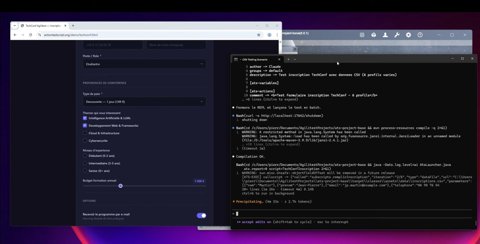
Étape 7 — Orchestration du script parent
Le script parent :
• Ouvre le navigateur
• Appelle le sous-script
• Transmet chaque ligne du CSV
• Ferme le canal
Cela crée une architecture en couches claire :
Script parent → sous-script fonctionnel sous-script Fichier de données
• Ouvre le navigateur
• Appelle le sous-script
• Transmet chaque ligne du CSV
• Ferme le canal
Cela crée une architecture en couches claire :
Script parent → sous-script fonctionnel sous-script Fichier de données
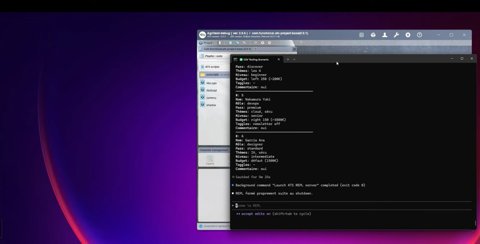
Étape 8 — Fichier de données généré
Le fichier CSV contient plusieurs profils variés :
• Étudiants
• Développeurs
• Profils seniors
• Différents budgets
• Champs facultatifs remplis ou vides
La couverture des tests est déterminée par la variation des données, et non par la duplication des scripts.
• Étudiants
• Développeurs
• Profils seniors
• Différents budgets
• Champs facultatifs remplis ou vides
La couverture des tests est déterminée par la variation des données, et non par la duplication des scripts.
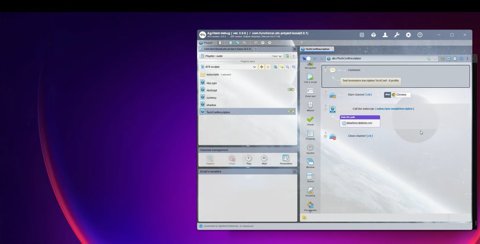

Étape 9 — Logique conditionnelle dans le sous-script
Le sous-script des conditions telles que :
IfNotEmpty($param(phone)) → enter value
Cela garantit :
• Les champs facultatifs sont traités correctement
• Les valeurs CSV vides n'interrompent pas le flux
• Le script reste générique et réutilisable
IfNotEmpty($param(phone)) → enter value
Cela garantit :
• Les champs facultatifs sont traités correctement
• Les valeurs CSV vides n'interrompent pas le flux
• Le script reste générique et réutilisable
Étape 10 — Exécution de l'ATS en mode compilé
Le REPL est fermé.
Le test est compilé et exécuté en ATS standard.
À ce stade :
• Aucune IA n'est requise
• Aucun runtime Claude n'est impliqué
• Le script s'exécute normalement dans CI/CD
Le résultat est un test fonctionnel pur ATS .
Le test est compilé et exécuté en ATS standard.
À ce stade :
• Aucune IA n'est requise
• Aucun runtime Claude n'est impliqué
• Le script s'exécute normalement dans CI/CD
Le résultat est un test fonctionnel pur ATS .
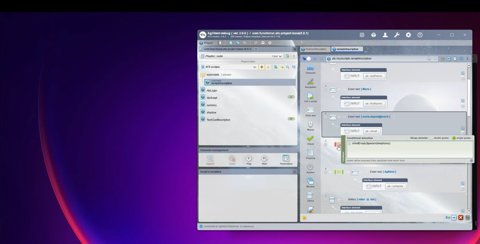
Ce que cela montre
Cette démonstration illustre trois principes essentiels :
1. Décomposition fonctionnelle
Un sous-script réutilisable sous-script Métier :
Remplir le formulaire
Gérer les valeurs facultatives
Valider le budget
2. Découplage des données
Le CSV est totalement indépendant :
Les scénarios de test évoluent sans toucher à la logique
De nouveaux cas sont ajoutés en modifiant uniquement les données
Les utilisateurs non techniques peuvent modifier la couverture des tests
3. Exécution déterministe
L'artefact final est :
ATS lisible par l'homme
Versionnable dans Git
Exécutable dans CI/CD
Indépendant de l'IA
L'IA accélère la phase de création.
ATS la stabilité de l'exécution.
1. Décomposition fonctionnelle
Un sous-script réutilisable sous-script Métier :
Remplir le formulaire
Gérer les valeurs facultatives
Valider le budget
2. Découplage des données
Le CSV est totalement indépendant :
Les scénarios de test évoluent sans toucher à la logique
De nouveaux cas sont ajoutés en modifiant uniquement les données
Les utilisateurs non techniques peuvent modifier la couverture des tests
3. Exécution déterministe
L'artefact final est :
ATS lisible par l'homme
Versionnable dans Git
Exécutable dans CI/CD
Indépendant de l'IA
L'IA accélère la phase de création.
ATS la stabilité de l'exécution.
Testez Agilitest pendant 30 jours. Sans engagement.
Et découvrez les avantages que vous pouvez tirer d'une automatisation intelligente des tests.
Les scénarios de tests peuvent être rejoués dans ATS, notre référentiel open source.
Gratuitement et pour toujours.
Gratuitement et pour toujours.

