
Pipelines multiples
Test automatiséPour un traitement rapide du pipeline au commit, d’autres en // sont créés pour y exécuter en tâche de fond les tests les plus lents et à valeur ajoutée moindre

Description
Un pipeline est un robot partagé qui traite chaque étape d'un processus de livraison, de la construction à son déploiement. Il vise à automatiser la livraison d'un incrément de produit prêt à être déployé [Humble 2011].
Un pipeline aide à [Edelman 2018] :
- Aller plus vite pour pouvoir répondre plus rapidement à l'évolution des besoins du Métier
- Améliorer la fiabilité pour tirer les leçons du passé, et améliorer la qualité/stabilité du système global.
Un pipeline est généralement composé de :
- une phase d'"intégration continue" (CI) qui consiste généralement à récupérer la source, à la compiler, à exécuter les tests et à effectuer d'autres contrôles pour garantir les normes de qualité (quality gates)
- une phase de "Continuous Delivery" (CD) qui consiste à déployer le bundle de livraison dans l'environnement approprié - cet environnement peut également être construit pendant cette phase
- une phase de suivi qui prend en compte les retours des utilisateurs finaux et génère des améliorations de la solution par le biais de ce backlog de produit ou d'actions correctives immédiates lorsque des incidents majeurs se produisent ; de nombreux termes peuvent faire référence à cette partie, tels que "Exploration continue" [SAFe 2021-46] ou "Exploitation continue" [Deloitte 2020].
Les phases peuvent comprendre différentes étapes telles que
- Fonctionnalités DevSecOps
- Étiquetage de sortie à la fin de l'IC
- Mise en place de l'infrastructure au moment du CD grâce aux fonctionnalités "Infrastructure as Code" (IaC) avec des serveurs immuables
Ces phases dépendent du niveau de maturité du produit et de l'organisation.

Cette idée de CI est née avec Grady Booch qui a proposé le terme pour la première fois dans son livre "Object-Oriented Analysis and Design with Applications" édité pour la première fois en 1991 et qui mentionnait également un paradigme de "Continuous Testing" [Booch 1994]. Les premières tentatives ont été faites en 1996 avec l'Extreme Programming (XP) de Kent Beck chez Daimler Chrysler [Fowler 2006] avec un pipeline nommé "Cruise Control" en 2001 : [Cosgrove 2021].
Le déploiement peut se faire de plusieurs façons [Ratcliffe 2012] :
- Big bang : tout se déploie en même temps
- Big Bang et Rolling Releases : des ensembles itératifs de fonctionnalités sont mis en place.
- Rolling Releases : mise à disposition des fonctionnalités dès qu'elles sont prêtes
- Livraison continue : publication de morceaux de code dès qu'ils sont suffisamment bons.
- Conception continue : CD combinée à la pensée conceptuelle itérative [Lewrick 2018], à la carte de l'empathie [Gray 2009], au Lean UX [Gothelf 2013] ou au Lean Startup [Ries 2012].
Ces stratégies impliquent des tailles d'émission, des délais de valorisation et des niveaux de risque différents.

Avec un pipeline, les changements peuvent être effectués avec une fréquence élevée en production pour assurer une amélioration continue au lieu d'une approche "big bang" qui réduit le risque inféré par les stratégies big bang [Duvall 2007] [Nygard 2018]. Cet état d'esprit de "faire les choses en continu" est souvent rencontré en agile : "si ça fait mal, faites-le plus fréquemment, et faites avancer la douleur" [Humble 2011]. Ainsi, un pipeline de build complet devrait être exécuté sur chaque commit, afin de livrer continuellement l'incrément de produit [Nygard 2018].
L'inconvénient évident de l'IC combinée à la CD est d'introduire aveuglément bugs en production [Edelman 2018], d'où la nécessité d'évaluer à plusieurs reprises le niveau de qualité avant le début de la phase de CD. Pour éviter cet écueil, le pipeline s'appuie sur les éléments suivants
- un état d'esprit "Automatisez tout ce que vous pouvez" pour prouver que le travail est fait à chaque nouveau changement [Humble 2011].
- un ensemble de tests unitaires qui déclenchent bugs afin de contrôler la régression ; cette méthode est appelée "Writing Tests for Defects" ou "Defect-Driven Testing" [Duvall 2007].
- contrôle de la version du code, des données de test et des scripts de construction/déploiement avec des validations fréquentes ; vous devez donc effectuer de petites modifications et valider après chaque tâche [Duvall 2007].
- construction automatisée avec une suite complète de tests automatisés et des mécanismes d'alerte [Humble 2011].
- procédures de retour en arrière intégrées dans le pipeline [Edelman 2018].
- accord de l'équipe pour soutenir la création, l'amélioration et le site maintenance du pipeline [Humble 2011].
Cela permet [Duvall 2007]
- étiqueter les actifs du dépôt de code,
- produire un environnement propre,
- l'exécution de tests reproductibles par rapport à une version bien définie et des retours en arrière pour viser la diffusion d'un logiciel fonctionnel à tout moment.
Pour ce faire, le pipeline s'appuie généralement sur des outils dotés d'une interface de ligne de commande (CLI) ou d'une API RESTful qui traitent principalement des données XML/HTML/JSON.
Enfin, même si le CI exécute des tests pour vous, une équipe expérimentée exécute localement les tests, puis intègre les modifications apportées par les autres membres de l'équipe [Humble 2011]. En termes de TDD, le CI devrait s'arrêter sur les tests RED (unitaires et autres). Si du code ROUGE est engagé, l'IC peut être exécuté et échouer. Les autres membres de l'équipe peuvent également tirer le code défaillant et le ralentir.
Pour éviter cela, le pipeline peut être exécuté à partir d'une branche temporaire, mais cela entraînerait des problèmes d'intégration si la fusion des branches se faisait tardivement.
Une approche plus mature consisterait à transformer le code en code VERT avant de s'engager. Malheureusement, dans la plupart des cas, cela ne suffit pas. L'utilisation d'outils de pipeline avec "pretested commit", "personal build", ou "preflight build"est alors nécessaire [Humble 2011].
Pour commencer, afin qu'un pipeline soit toujours disponible pour la livraison, l'état d'esprit devrait être de "ne jamais rentrer chez soi sur une version cassée", même si cela signifie faire votre dernière livraison une heure avant de terminer votre journée [Humble 2011].
Pour permettre la haute disponibilité, il est nécessaire de surveiller l'état du pipeline pour permettre une réaction Andon lorsque tout le monde est responsable du pipeline [Humble 2011] et d'introduire Jidoka à partir des défauts rencontrés sur le code de production [Duvall 2007] et des faux positifs également pour rendre le pipeline plus robuste [Moustier 2022]. Pour améliorer le pipeline et en faire un pipeline "toujours VERT", les équipes peuvent être amenées à revenir en arrière si une correction n'est pas fournie dans un délai donné [Humble 2011].
La correction immédiate des versions cassées doit être une priorité absolue du projet [Duvall 2007]. Cette approche est en fait une approche Kaizen qui vise à atteindre le "zéro défaut" [Lindström 2020].
Impact sur la maturité des tests
L'IC est l'une des 13 pratiques revendiquées par XP [Beck 2001]. Aujourd'hui, la plupart des équipes essaient d'intégrer l'ensemble des phases du pipeline. La raison en est que sans IC, les changements de logiciels sont souvent effectués par lots importants, ce qui peut prendre des mois avant d'obtenir un retour d'information sur les fonctionnalités.
Ce manque de retour d'information est également dû au manque de personnes qui ne sont pas intéressées par la gestion de l'ensemble du produit jusqu'à ce qu'il soit terminé [Humble 2011]. L'être humain a tendance à se concentrer sur la mise en œuvre au point de ne plus voir la situation dans son ensemble, simplement parce qu'il faut faire un effort supplémentaire pour sortir le nez du guidon. L'inconvénient de ce type de situation est qu'il génère des boucles de rétroaction incroyablement longues, et qu'il faut également beaucoup de temps pour que les problèmes soient traités. En conséquence, le développement des fonctionnalités prend beaucoup plus de temps et la qualité du service s'en trouve réduite. [Edelman 2018] [Humble 2011].
En fait, la présence d'un pipeline permet aux développeurs d'apporter simplement des modifications et de les transférer directement en production grâce à un pipeline rapide. Cela permettra aux membres de l'équipe d'avoir un retour rapide sur l'ensemble de la solution [Duvall 2007]. Pour générer un bon flux de livraison requis en agile, un pipeline de 10' au niveau du cycle de développement est également un objectif [Humble 2011]. Ce délai est une sorte de SMED pour les clients qui tire parti de l'agilité de leur propre Métier [SAFe 2021-40] ; par conséquent, l'IC est une pièce maîtresse pour la qualité et fournit donc les fondations techniques pour une approche de Test Continu [Duvall 2007].
Le délai de 10 minutes ci-dessus est en fait un objectif difficile à atteindre. Les difficultés proviennent de la grande quantité évidente de tests candidats à l'exécution par le CI/CD ainsi que des nombreuses tâches effectuées au CI, notamment
- construction de binaires à partir du code de production
- inspections continues [Duvall 2007] (qualité du code, couverture du code, duplication du code),
- Génération d'environnement à la demande [Edelman 2018]
- L'importance deDevSecOps
- génération de la documentation
Par conséquent, vous devez
- maintenir un processus de construction et de test court [Humble 2011] - notamment en n'exécutant que des contrôles de sécurité dans l'IC qui devraient couvrir la plupart des fonctionnalités
- des composants factices qui introduiraient des retards et des tests difficiles à répéter en raison de l'accès au réseau ou à la base de données [Duvall 2007].
Par conséquent, toutes les permutations et tous les cas limites hors du contrôle d'intégrité doivent être exécutés séparément [Axelrod 2018] avec des constructions secondaires ou à intervalles réguliers [Duvall 2007] avec des pipelines supplémentaires. Ces pipelines doivent correspondre à votre flux de livraison et aux niveaux d'attente des boucles de rétroaction.
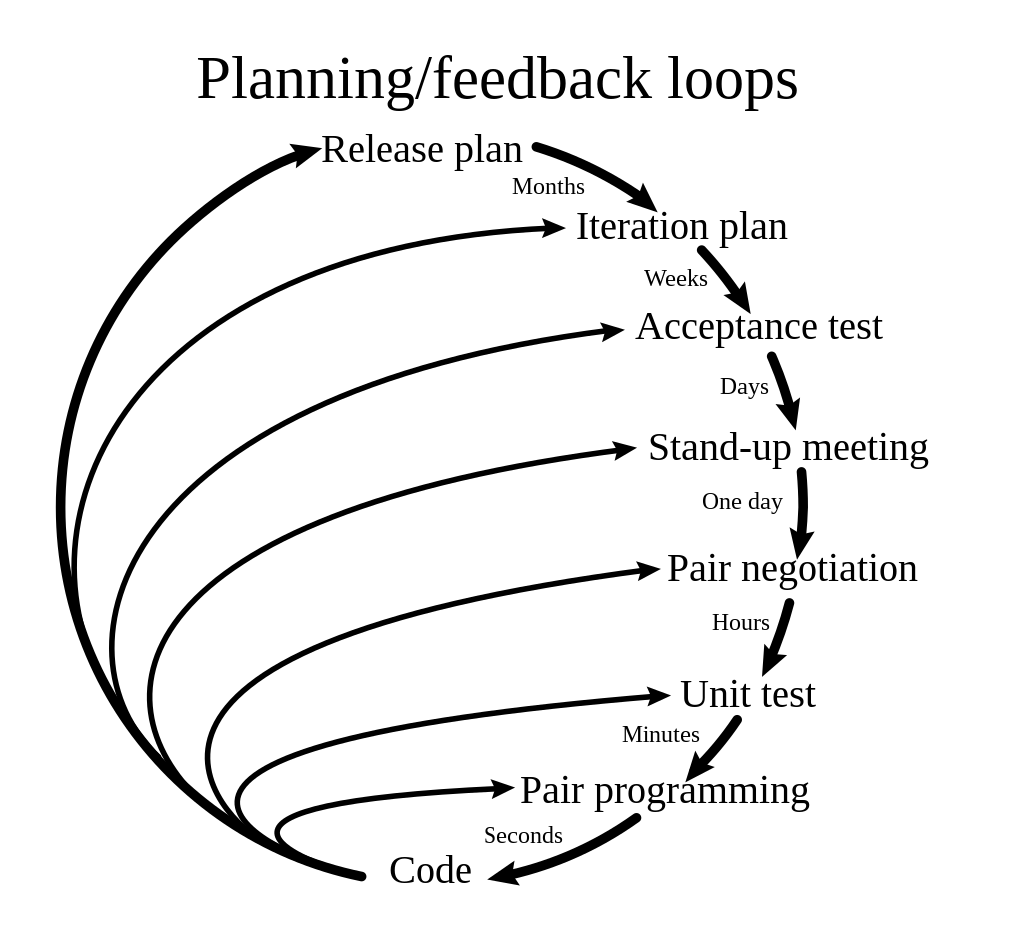
Ces boucles de rétroaction devraient adapter le contenu du pipeline avec un compromis entre
- boucles de rétroaction attentes
- timebox lié à la durée de la boucle
- les durées des scripts pour qu'ils correspondent à la timebox
- Shift Left Testing qui nécessite des retours d'information dès que possible.
Cela met en évidence la nécessité de prévoir plusieurs filières pour résoudre le problème des délais, par exemple :
- un pipeline CI/CD synchrone de 10' déclenché juste après la validation de certains changements de code
- un pipeline CI/CD asynchrone lancé par exemple la nuit avec un délai de quelques heures
- un CI/CD à durée limitée pour exécuter des scripts très lents, tels que l'analyse SAST [Hsu 2018], les tests de charge ou les migrations de données [Nygard 2018], qui peuvent durer plusieurs jours.
Lorsqu'il s'agit de grandes entreprises, l'utilisation de plusieurs pipelines fonctionnant en parallèle devient encore plus évidente, car il faudrait des jours pour construire plusieurs millions de lignes de code à la fois. L'architecture et l'organisation devraient alors faciliter la conception des pipelines, notamment grâce à
- microservices [Nygard 2018]
- Pipelines basés sur la chaîne de valeur [SAFe 2021-18].
- ou inspiré de l'approche "Team Topology" [Skelton 2019].
Dans ce contexte, travailler de manière cadencée et synchronisée devient aussi difficile que stimulant ; heureusement, cela peut être facilité par les stratégies Dark Launch / Canary Releasing qui rendent le processus de livraison résistant aux problèmes de timing.
Si la stratégie d'automatisation de l'organisation rend possible des scripts de test de bout en bout avec de multiples parties fournies par plusieurs départements, le besoin d'un pipeline pour les rassembler tous émerge, l'utilisation d'une CMDB décentralisée suit [Humble 2011] ainsi que l'utilisation de drapeaux à bascule pour contrôler la configuration de ces environnements.
Le point de vue d'Agilitest sur cette pratique
Agilitest est extrêmement concerné par la question du DevOps, c'est pourquoi l'outil peut être branché à Jenkins, l'orchestrateur le plus utilisé dans les entreprises de logiciels.
Comme les scripts Agilitest sont enregistrés sous un format texte, ils peuvent facilement faire partie de la CMDB avec Git. Le format texte permet de fusionner les scripts avec un simple éditeur de texte.
L'outil peut être impliqué à tous les niveaux des pipelines, depuis l'équipe de développement jusqu'à la gestion du produit, grâce à son approche #nocode puisqu'il ne nécessite aucune compétence en matière de développement.
La diffusion des scripts Agilitest à travers l'organisation est également facilitée par un moteur d'exécution de scripts open source [Pierrehub2b 2021]. Il permet ainsi la mise à l'échelle de l'automatisation des scripts de test de manière gratuite.
Pour découvrir l'ensemble des pratiques, cliquez ici.
Cartes connexes
Pour aller plus loin
- [Beck 2001] : Kent Beck & Cynthia Andres - 2001 - "Extreme Programming Explained : Embrasser le changement" - isbn:9780321278654
- [Booch 1994] : Grady Booch - 1994 (1ère édition 1991) - "Object-Oriented Analysis and Design with Applications" - isbn:97805353402
- [Cosgrove 2021] : Kat Cosgrove - OCT 2021 - "Une histoire du CI/CD" - https://www.youtube.com/watch?v=aRlgmbSEhbQ
- [Deloitte 2020] : Deloitte - APR 2020 - "DevOps Point of View An Enterprise Architecture perspective" - https://www2.deloitte.com/content/dam/Deloitte/nl/Documents/technology/deloitte-nl-etp-devops-point-of-view.pdf (en anglais)
- [DonWells 2013] : DonWells - JUL 2013 - "Planification et boucles de rétroaction dans la programmation extrême" - https://en.wikipedia.org/wiki/Extreme_programming#/media/File:Extreme_Programming.svg
- [Duvall 2007] : Paul M. Duvall & Steve Matyas & Andrew Glover - 2007 - "Continuous Integration : Améliorer la qualité des logiciels et réduire les risques" - isbn:9780321336385
- [Edelman 2018] : Jason Edelman & Scott S. Lowe & Matt Oswalt - 2018 - "Programmabilité et automatisation des réseaux" - isbn:9781491931257
- [Fowler 2006] : Martin Fowler - MAI 2006 - "Intégration continue" - https://martinfowler.com/articles/continuousIntegration.html
- [Gothelf 2013] : Jeff Gothelf & Josh Seiden - " Lean UX - Applying Lean Principles to Improve User Experience " - O'Reilly - ISBN : 978-1-449-31165-0
- [Gray 2009] : Dave Gray - " Carte de l'empathie " - 12/NOV/2009 - https://gamestorming.com/empathy-map/
- [Hsu 2018] : Tony Hsu - 2018 - "Hands-On Security in DevOps : Ensure Continuous Security, Deployment, and Delivery With DevSecOps" - isbn:9781788995504
- [Humble 2011] : Jez Humble - 2011 - "Continuous Delivery : Reliable Software Releases Through Build, Test, and Deployment Automation" - isbn:9788131757369
- [Lewrick 2018] : Michael Lewrick, Patrick Link & Larry Leifer - " The Design Thinking Playbook Mindful digital transformation of teams, products, services, businesses and ecosystems " - Wiley - 2018 - ISBN 978-1-119-46747-2.
- [Lindström 2020] : John Lindström, Petter Kyösti, Wolfgang Birk & Erik Lejon - JUL 2020 - "Un modèle initial pour la fabrication zéro défaut" - https://mdpi-res.com/d_attachment/applsci/applsci-10-04570/article_deploy/applsci-10-04570.pdf
- [Moustier 2022] : Christophe Moustier - AVR 2022 - "Mon Flaky Test est agile !" - https://www.youtube.com/watch?v=Ptg5NICosNY&t=2708s
- [Nygard 2018] : Michael T. Nygard - 2018 - "Release It ! Concevoir et déployer des logiciels prêts pour la production" - isbn:9781680502398.
- [Pierrehub2b 2021] : Pierrehub2b - MAI 2021 - "Projet actiontestscript" - https://github.com/pierrehub2b/actiontestscript
- [Ratcliffe 2012] : Lindsay Ratcliffe & Marc McNeill - AUG 2012 - "Agile Experience Design : A Digital Designer's Guide to Agile, Lean, and Continuous" - isbn:9780321804815
- [Ries 2012] : Eric Ries - " Lean start-up " - Pearson - 2012 - ISBN 978-2744065088
- [SAFe 2021-18] : SAFe - FEV 2021 - "Value Stream" - https://www.scaledagileframework.com/value-streams/
- [SAFe 2021-40] : SAFe - JUL 2021 - "Métier Agility" Métier https://www.scaledagileframework.com/Métier-agility/
- [SAFe 2021-46] : SAFe - FEV 2021 - "Pipeline de livraison continue" - https://www.scaledagileframework.com/continuous-delivery-pipeline/
- [Skelton 2019] : Matthew Skelton & Manuel Pais - 2019 - "Team Topologies : Organiser des équipes Métier et technologiques pour un flux rapide" - isbn:9781942788829


{kind=link}